
Bite2Text Dataset
This page describes the Bite2Text dataset, introduced in the ODIN2026 challenge series for multimodal orthodontic report generation from intraoral data. This benchmark is developed by the University of Modena and Reggio Emilia, the University of Ferrara, and Radboud University Medical Center, Bite2Text is part of the ODIN2026 challenges at MICCAI 2026.
Dataset Focus
Orthodontic Reporting. The dataset allow to develop models able to generate clinically meaningful reports describing malocclusion patterns, occlusal relationships, crowding or spacing, and treatment-relevant findings.
Multimodal Reasoning. 3D intraoral geometry and 2D intraoral photographs should be jointly processes to produce coherent, clinically aligned text.
Robustness Across Centers. The benchmark data are collected from multi-center training data and a hidden private test set from external institutions to assess generalization under domain shift.
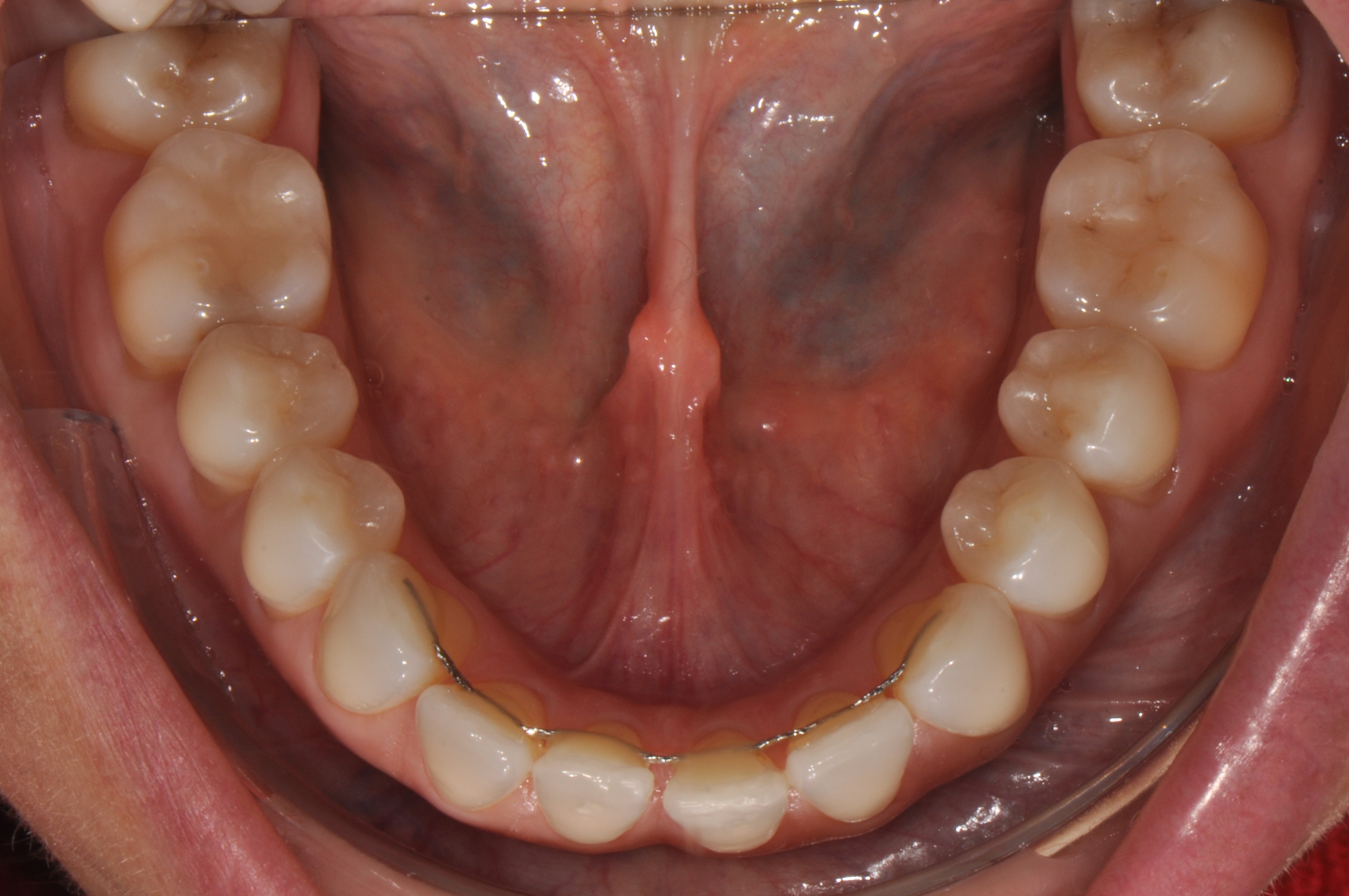
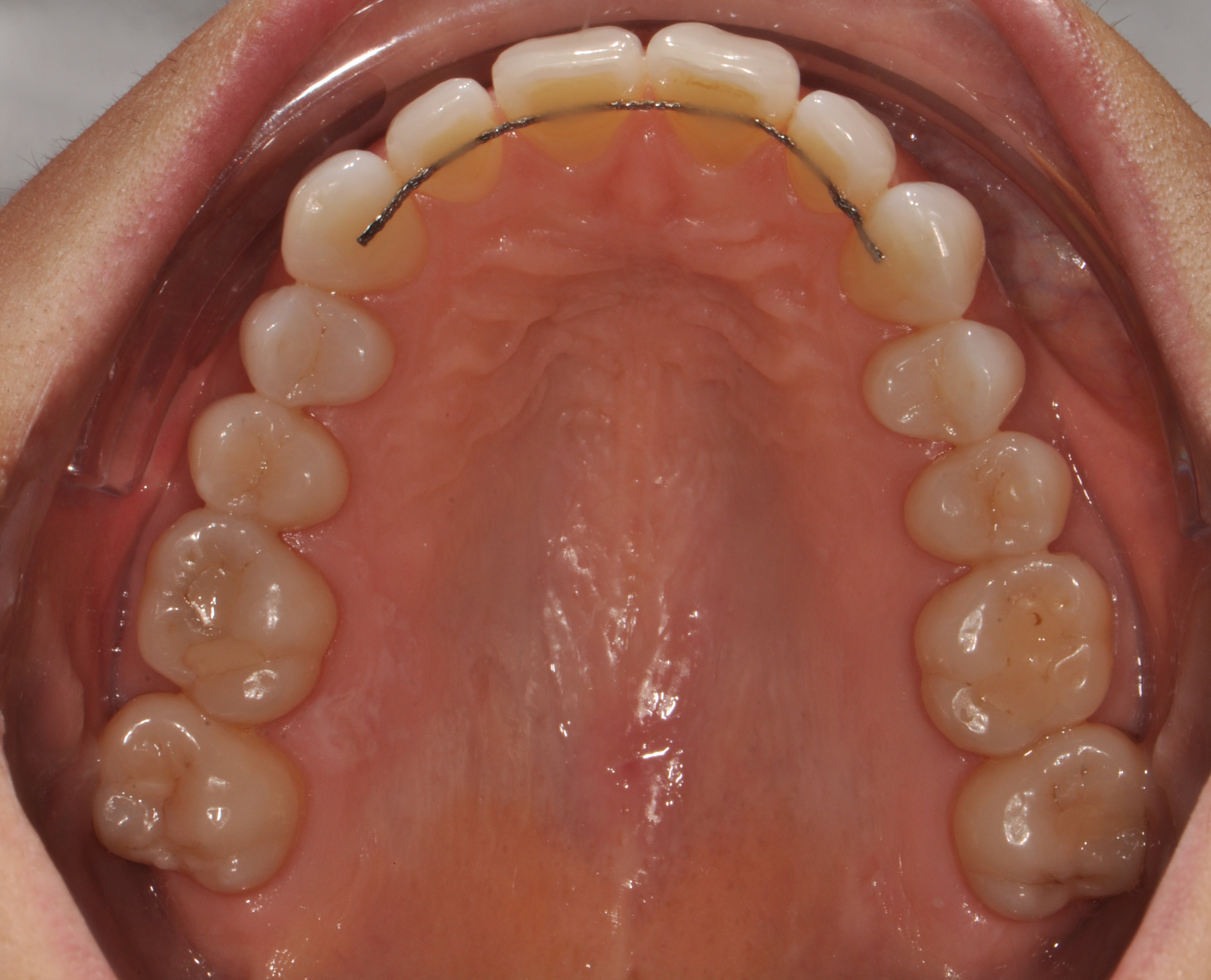
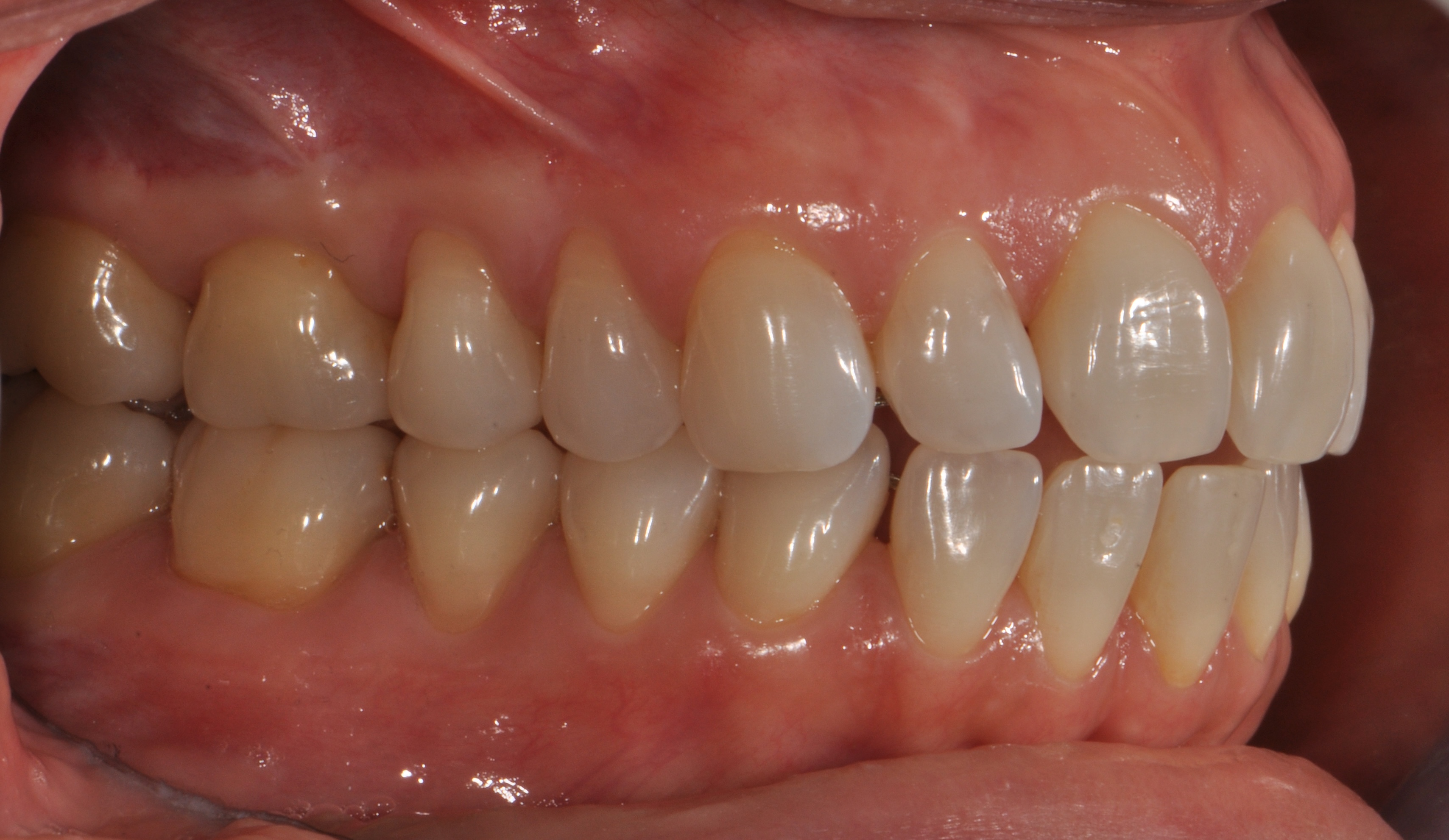
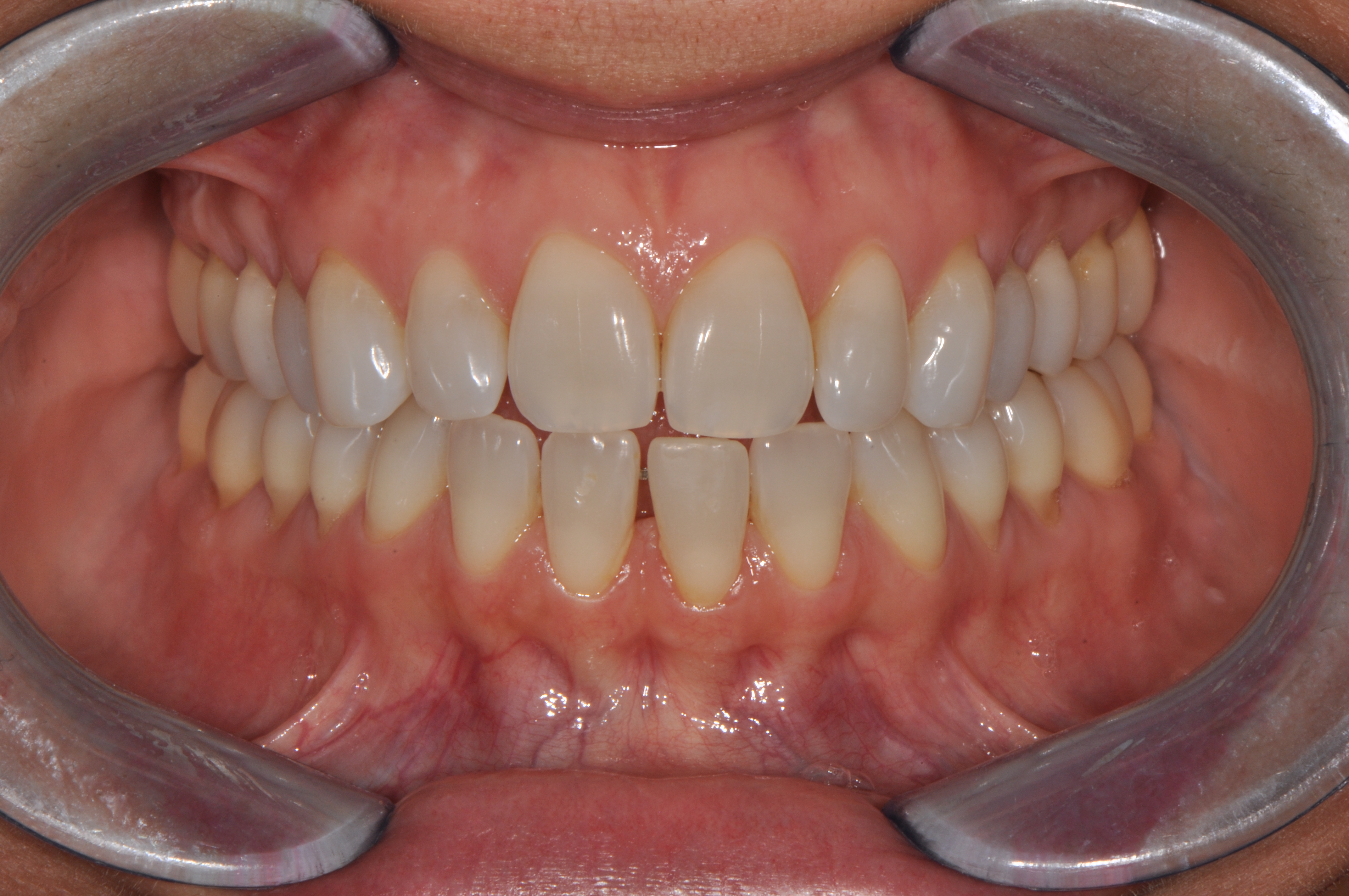
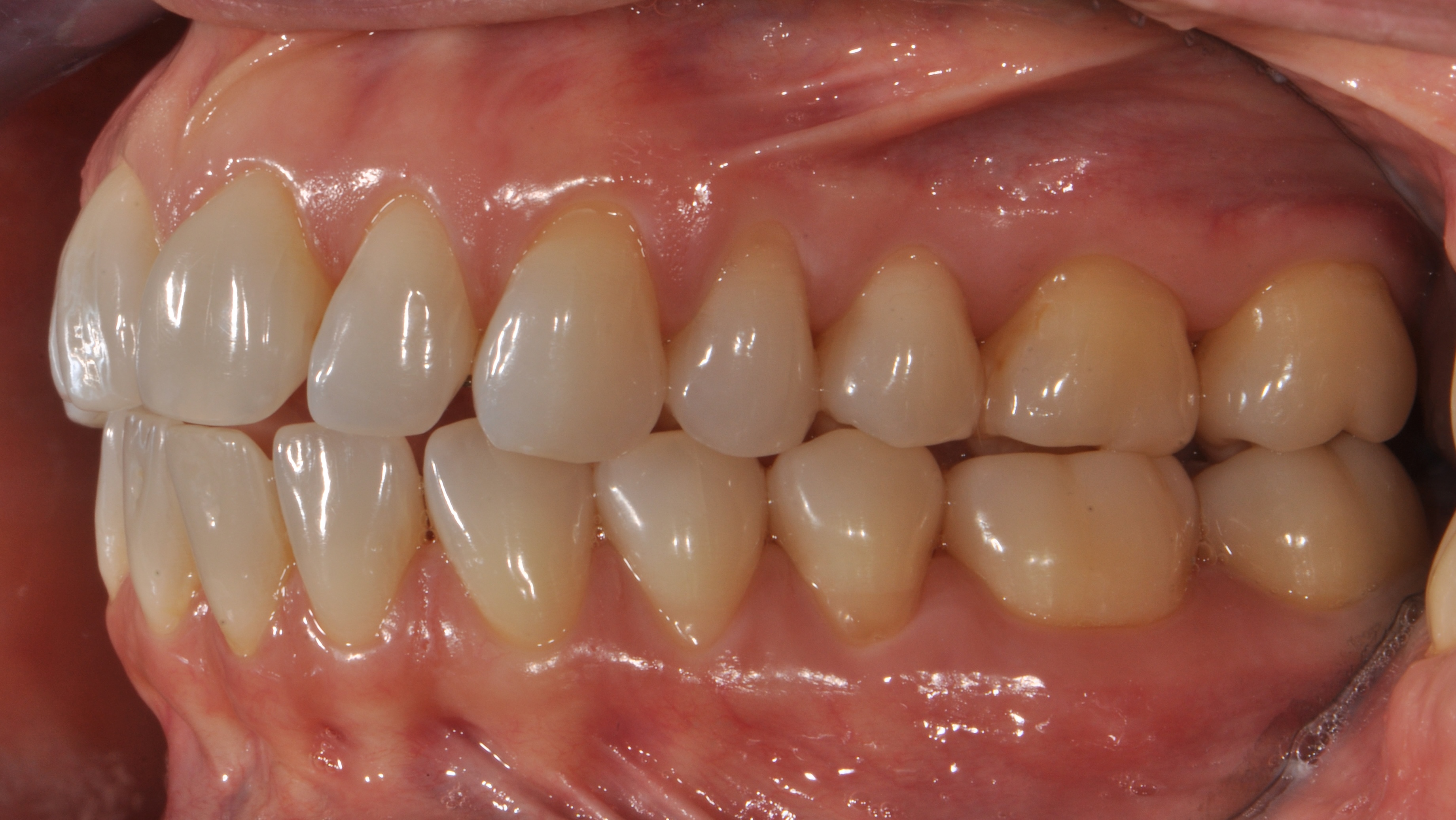
Dataset Structure
| Field | Value |
|---|---|
| Training cases | 2,000 patients (currently 1,000 released) |
| Private test cases | 50 patients (hidden) |
| 3D input modality | Upper and lower intraoral scans (IOS) |
| 2D input modality | Standardized intraoral RGB photographs |
| Annotation format | Clinician-authored textual reports (original and English translation) |
| License | CC BY-NC-SA |
Each case is organized as:
ios/: upper and lower 3D intraoral scans,photos/: corresponding standardized intraoral photographs,reports_it/: original clinician-authored reports,reports_en/: English-translated reports.
Loading 3D models...
Interactive 3D visualization. Lower jaw is shown in blue, upper jaw in red.

Clinical Context
Bite2Text reflects routine orthodontic workflows where clinicians inspect intraoral scans and photographs to describe occlusal relationships, alignment patterns, and treatment-relevant anomalies.
The objective is to support high-quality draft reporting that reduces manual documentation time, improves inter-observer consistency, and enables reliable multi-center clinical decision support.
The training set aggregates acquisitions from multiple centers, scanners, and clinical environments. The hidden test set is sourced from centers not included in training, enabling rigorous evaluation of deployment-oriented generalization.
Download
Ethical approvals: training data release is covered by local approvals from the University of Ferrara (No. 262/2025/Oss/UniFe) and the Digital Research Center of Sfax (No. PV-CS-08/01/2026). The hidden test set was exempted by METC Oost-Nederland (file 2026-18852).
If you use our dataset, you must cite the following papers.
text loading...
Copy