ToothFairy3 Dataset
This page describes the dataset associated with the ToothFairy3 challenge, a challenged organized by the University of Modena and Reggio Emilia with the collaboration of Radboud University. The challenge is hosted by grand-challenge and is part of the ODIN2025 workshop within MICCAI2025. For challenge details, please visit the dedicated website. The dataset used to run the challenge and here described is an extension and improvement of previously released datasets, Maxillo, ToothFairy, and ToothFairy2.
Features
The table below resumes the core information about the (training) dataset released for ToothFairy3 challenge.
Although with additional annotations, volumes of "Set A" (marked with a leading P in the file name) and "Set B" (marked with a leading F in the file name) overlaps with those of the ToothFairy2 dataset. Data from "Set B" have a broader field of view containing the complete upper teeth segmentations. The acquisition machine for "Set A" and "Set B" is the same. Data from "Set C" (marked with a leading S in the file name) were not previously released with the ToothFairy2 datasets and have been acquired from a different machine. The field of view of "Set C" is similar to that in "Set A".
What’s new in ToothFairy3:
- 🦷 52 new CBCT volumes, acquired using a different scanner;
- 🧠 35 additional labels, including pulpy cavities for all 32 teeth, as well as left/right incisive canals and the lingual canal;
- ✅ Improved annotations from ToothFairy2.
| Field | Value |
|---|---|
| Set A | 417 |
| Set B | 63 |
| Set C | 52 |
| File Format | NIfTI |
| Values Scale | Hounsfield |
| Dataset Classes | 77 (the complete list is available in the dataset.json file) |
| Max Volume Shape | (298, 512, 512) |
| Min Volume Shape | (170, 272, 345) |
| Median Volume Shape | (168, 362, 371) |
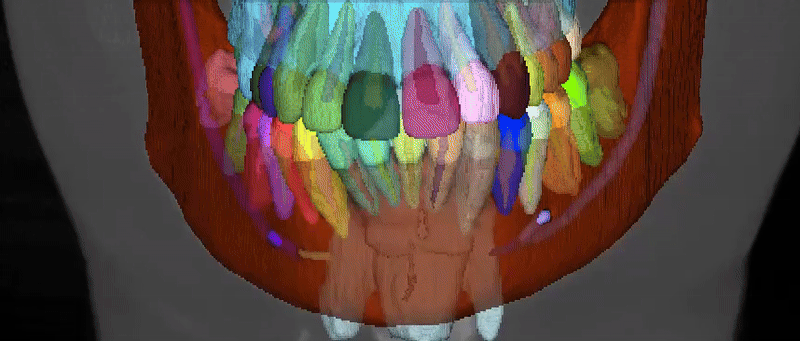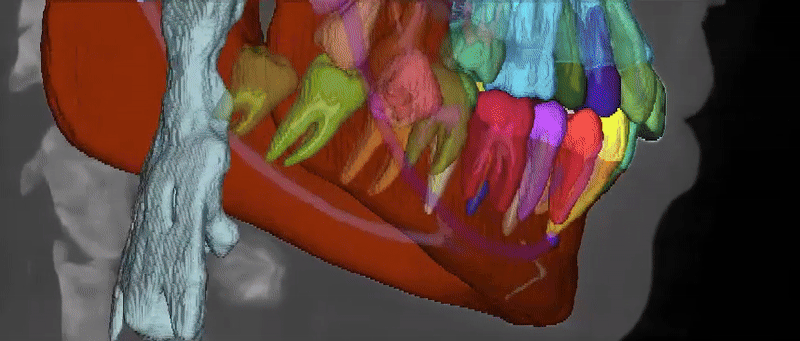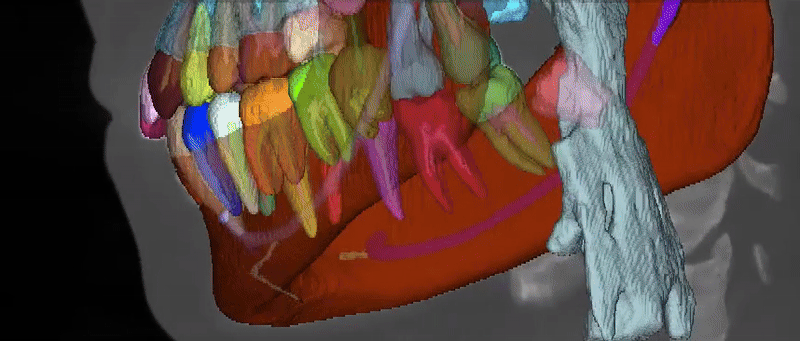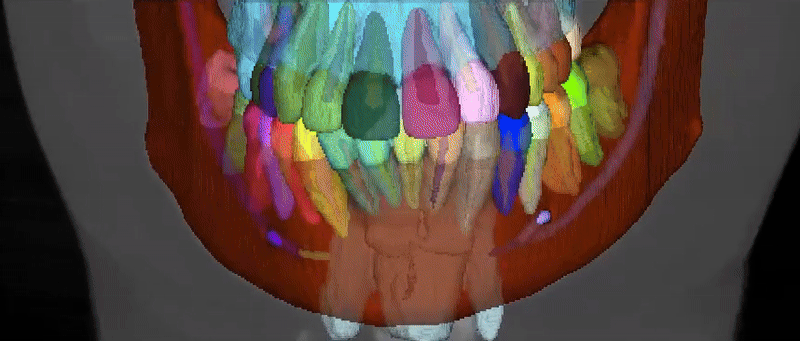

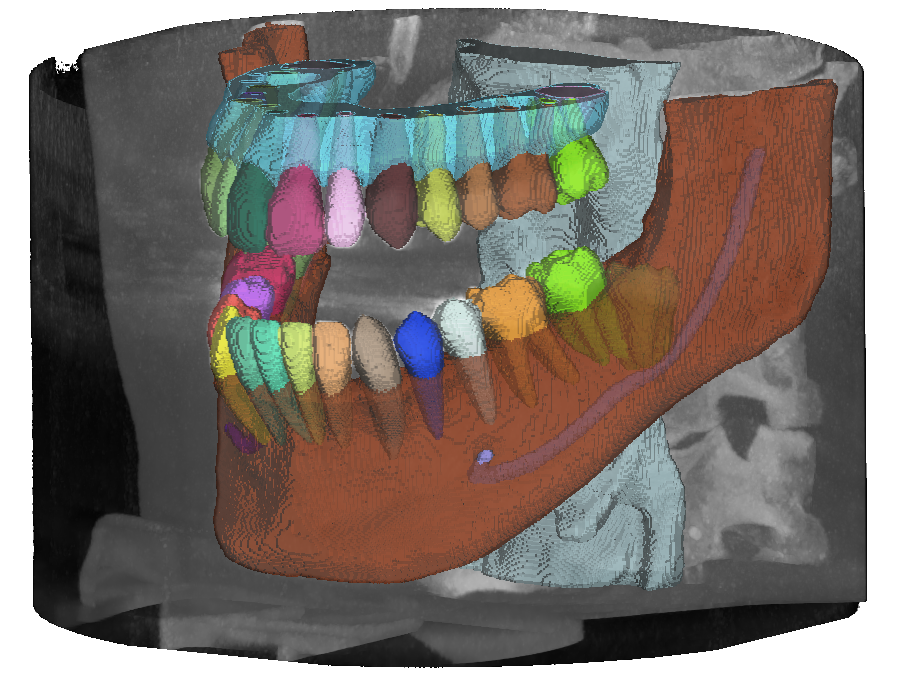
Dataset Structure
The ToothFairy3 dataset follows the nnU-Net dataset format. Datasets consist of three components: raw images, corresponding segmentation maps and a dataset.json file specifying some metadata. Data are available in NIfTI format. The class IDs are an extension of the FDI World Dental Federation notation and include: Background, Jaws, Inferior Alveolar Canals, Maxillary Sinus, Pharynx, Bridges, Crowns, Implants, Upper and Lower Teeth (Wisdom Teeth included), Incisive Canals, Lingual Canal, and Teeth Roots/Pulps for a total of 77 classes.
Radiological Orientation
This dataset uses the RPI orientation, which is not a standard convention, but it is consistent with the first release of the the Maxillo Dataset.
If you wish to convert the dataset to the standard LPS orientation, you can use this Python script. The script requires two input parameters:
- the path to the dataset (with
imagesandlabelssubfolders), and - the output path where the transformed files will be saved.
Note: If you are participating in the ToothFairy Challenge, this transformation is not required. The orientation of all test data matches that of the training data as provided on this website.